---
title:
Yet another batch of meaningless autonomous agent benchmarks :)
date:
2026-06-12
draft:
false
---
https://github.com/korchasa/flowai-experiments/tree/main/agents-comparison
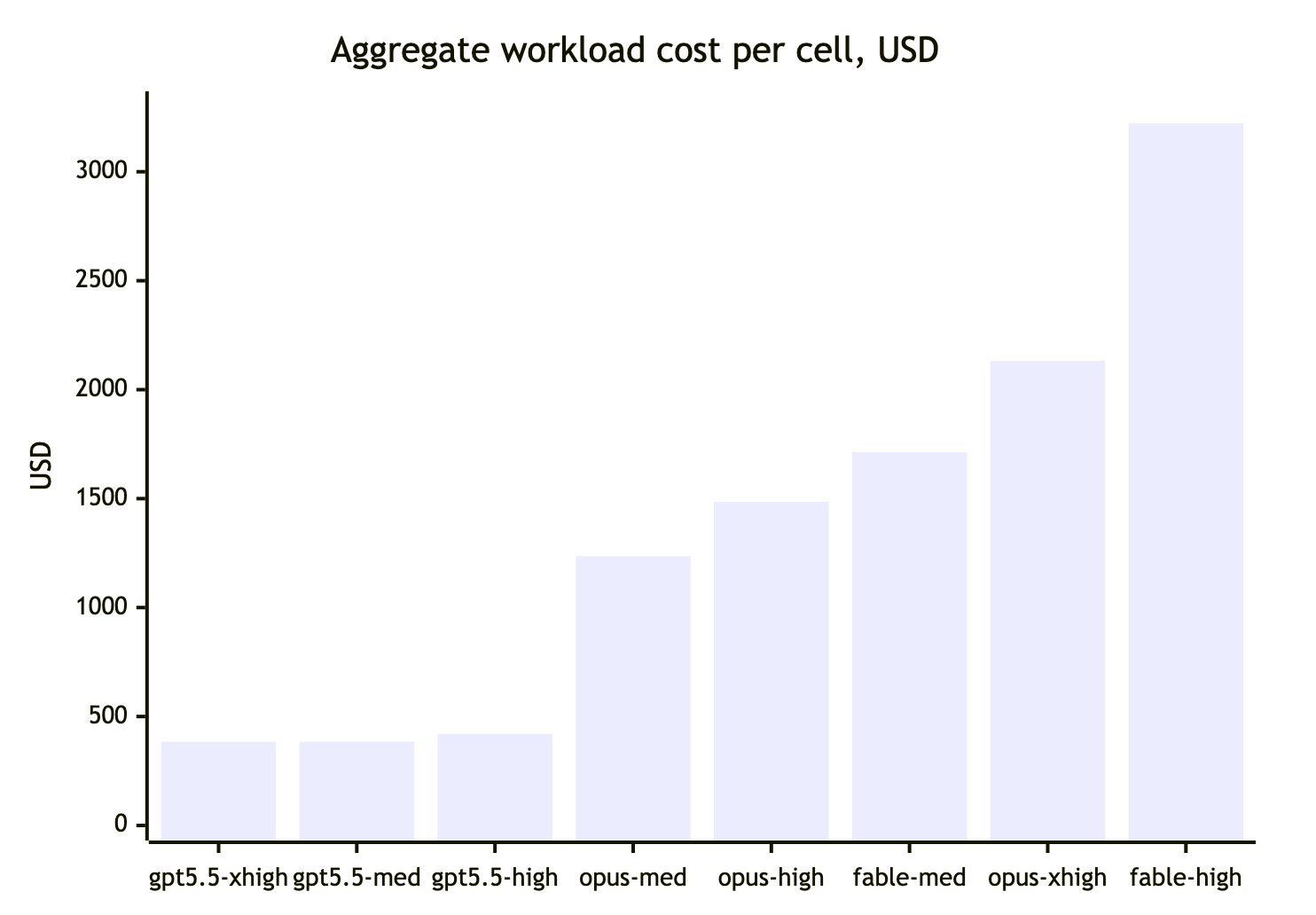
Burned 40% of my limit running benchmarks close to my real tasks on opus/fable/gpt-5.5 — fully autonomous agent work: app generation from scratch, a project audit, and three implementation tasks of varying difficulty.
What can be said with at least some confidence:
- fable beats opus-4.8 and gpt-5.5 on result quality. My working hypothesis: fable medium = opus xhigh.
- opus xhigh is unexpectedly expensive due to overly long reasoning. Sometimes more expensive than fable.
- Looks are still a pain. Everything is dark-neon-identical.
- Proper testing will take 1-2 weekly limits on claude x20.
Hypotheses:
- The best model choice will depend on the project’s stage of development.
- In some cases, more expensive but higher-quality models can be justified even on cost over the span of a single task, without counting technical debt.
- Beyond some threshold, longer reasoning no longer improves quality — it only increases cost.